


The uncomfortable truth about AI-assisted development, and why structure beats instructions every time.
Here’s something I’ve known for a long time, but the deeper I get into AI-assisted development, the more I realize just how true it is: the strongest signal for good code is good code.
If your codebase is clean and consistent, your AI agent will write code that fits right in. If your codebase is a mess, the agent will faithfully continue the mess. Not because it’s bad at coding. Because it’s very good at pattern-matching.
There is no magic instruction you can put in your CLAUDE.md that overrides this. The codebase is the instruction. Everything else is noise. A recent paper confirmed what many of us suspected: those instruction files tend to reduce task success rates while increasing inference cost by over 20%. We’re not just wasting effort. We’re actively making things worse.
The real problem isn’t instructions. It’s incentives. And it’s on you, the human, to get them right. Here are my takeaways from thousands of hours working with AI coding agents.
The Age of the Instruction File
AGENTS.md, CLAUDE.md, .cursorrules. If you’ve used an AI coding agent for more than a week, you’ve written at least one of these. Agent uses wrong package manager? Add it to the instruction file. Agent forgets to run tests? Add it. Agent writes code that doesn’t match your style? Believe it or not, add it.
I’ve done all of the above. And honestly, it feels like the right thing to do. Over 60,000 repositories now include some form of agent context file, and the assumption behind all of them is intuitive: more context equals better behavior. It’s how we’d onboard a human teammate. Write it down, hand them the doc, trust the process.
But here’s the thing: an LLM is not a human teammate. It doesn’t internalize values from a README the way a junior dev eventually “gets” your codebase culture. It processes tokens and follows the path of least resistance toward task completion. That carefully written instruction file? It’s competing for attention with the system prompt, the task description, the code the agent just read, and every tool output it’s processing. Think of it less like onboarding documentation and more like one voice in a crowded room.
Which raises a question I don’t think enough people were asking: does any of this actually work?
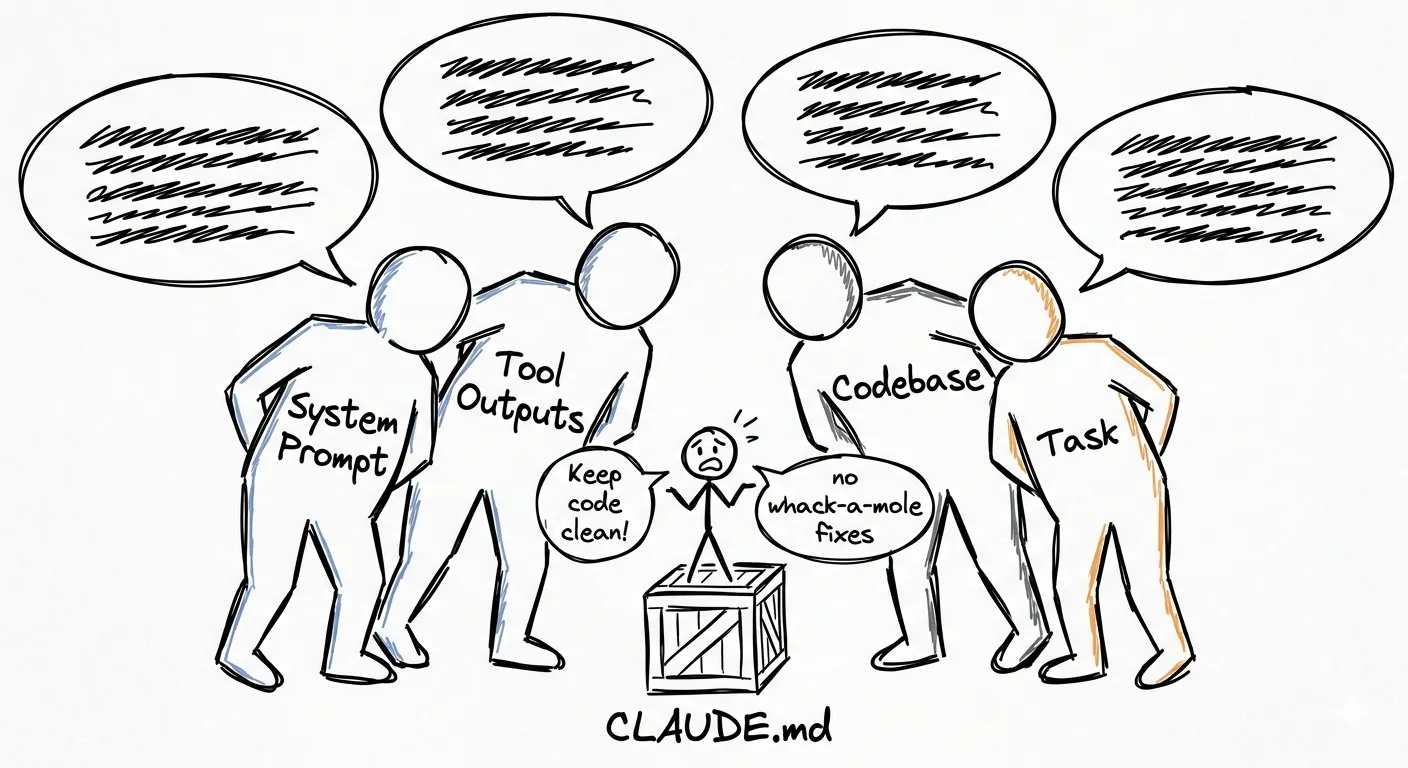
The Research Says Otherwise
In February 2026, researchers from ETH Zurich published Evaluating AGENTS.md, the first rigorous study on whether context files actually help coding agents. They tested across multiple agents and LLMs, on both SWE-benchmark tasks and real-world issues from repositories with developer-written context files.
The results were pretty damning. Context files tended to reduce task success rates compared to providing no context at all. Inference cost increased by over 20%. The agents weren’t just ignoring instructions. They were spending extra tokens processing them and then performing worse.
Here’s the practical takeaway, and I think it’s the quickest win in this entire post: a 5-line CLAUDE.md addressing your project’s specific, repeated quirks will outperform a 1,000-word generated overview every time. Instructions should be earned through repeated failure, not written upfront.
More Context Isn’t the Answer. Better Patterns Are.
So if instruction files don’t work, what about the fancier alternatives? RAG-powered context retrieval, auto-memory systems, agent memory graphs, knowledge bases that automatically index your codebase. These are more sophisticated than a static markdown file, but they share the same core assumption: if we just give the agent the right context, it will make better decisions.
I’ve experimented with most of these. The pattern is always the same. The solution starts lean and useful. Over time it accumulates noise. Auto-memory fills up with notes the agent wrote about itself, with no human review of whether those notes are accurate. RAG expands the very context window that research shows is already too crowded. And if the underlying codebase has bad patterns, you’re just indexing those bad patterns more efficiently.
These tools aren’t worthless. RAG is genuinely useful for navigating large codebases. Auto-memory has its place. But they’re treating symptoms.
And this is where it gets dangerous. Because bad patterns don’t just persist. They compound.

Picture this: your AI agent makes a questionable structural choice in session 1. Nothing terrible, just a slightly wrong abstraction. In session 2, the agent reads the codebase, sees that pattern, and follows it. By session 5, the bad decision is load-bearing. By session 10, refactoring means rewriting half the project.
A human developer might catch this at session 3 and refactor early. An AI agent doesn’t “realize” anything. It sees what’s there and continues the pattern. Every. Single. Time.
This is the real danger of autonomous AI development. Not that agents write bad code, but that bad decisions compound faster than any human can catch them. If the patterns in your codebase are good, you get a virtuous cycle. If they’re bad, you get a death spiral. And no amount of context injection will save you from a death spiral. The only reliable path to good AI-generated code is to never stray too far from good code in the first place.
The Real Problem: Incentives
Your agent’s only goal is to complete the current task. That sounds obvious, but sit with it for a second, because the implications are bigger than they seem.
I keep running into two blind spots that no documentation can fix.
The bug-next-door problem. Your agent is working on a feature. It encounters an obvious, unrelated bug two lines away. It doesn’t stop. It doesn’t file a ticket. It doesn’t even mention it. Because the task is the feature, not the bug. The model isn’t ignoring your instructions. It’s prioritizing correctly given its one objective.
The tunnel vision problem. Your agent discovers mid-task that a better architectural approach exists. It won’t pursue it. Refactoring isn’t the task. It will implement the feature using the existing (worse) approach, ship it, and move on. I’ve watched this happen more times than I can count, and it’s genuinely frustrating once you start noticing it.
You can’t instruct your way out of a structural misalignment between what you want (great software) and what the agent wants (task completion). Those are different goals.
What Actually Works: The Exoskeleton Approach
Now for the positive news: AI is not bad at improving your codebase. It’s actually very good at it. The problem is that improving the codebase is never the prime directive unless you make it one.
When you say “implement feature X” and your CLAUDE.md says “keep architecture clean,” the agent will care about feature X. But flip it around. Make the prime directive “refactor the authentication module based on these specific learnings,” and the agent will do excellent work. Same model, same capabilities, completely different outcome. The issue was never intelligence. It was always priority.
So the real question becomes: how do I collect the signals that matter, so I can hand them to the agent as the actual task?
Two mechanisms I’ve found that work:
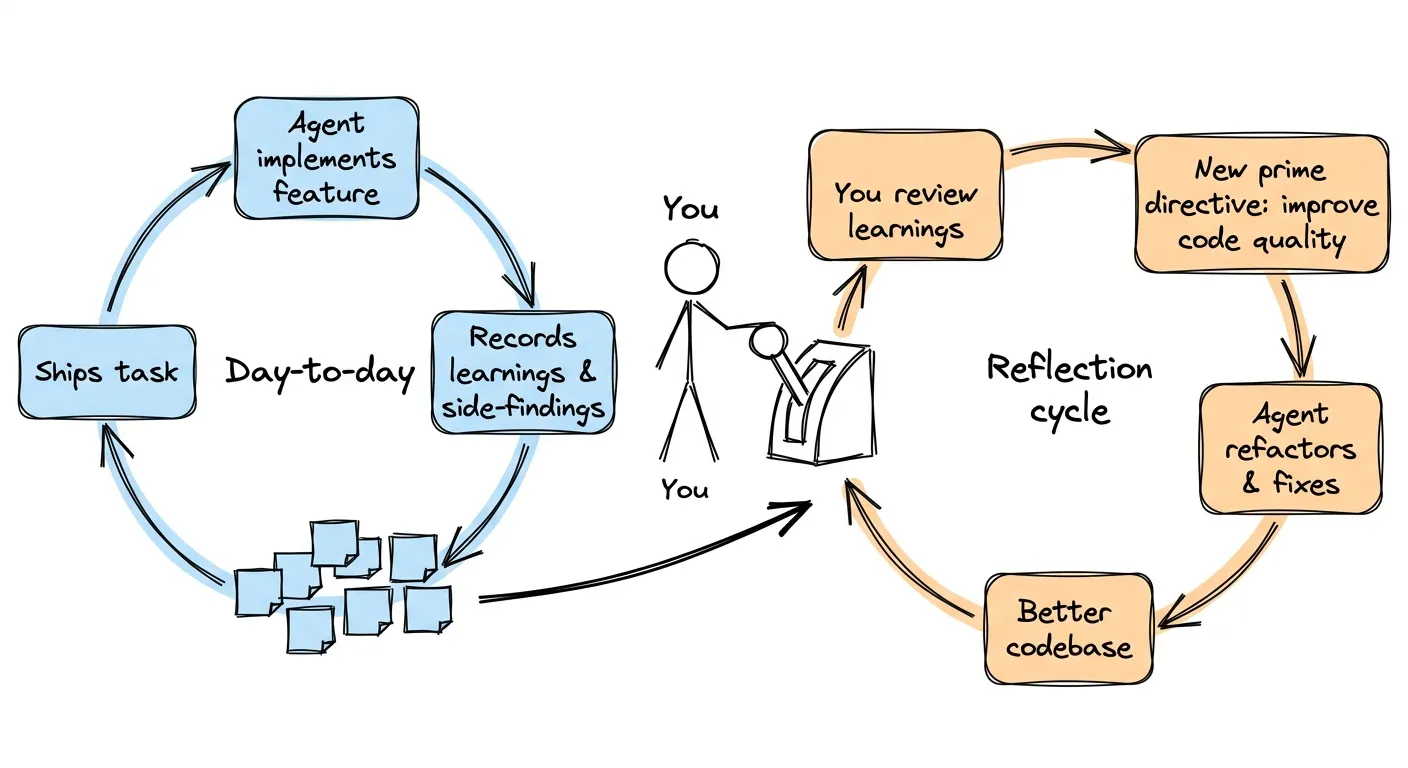
A place for “not now.” When an agent spots something outside its current task, it needs somewhere to put that finding. Not a memory system, not a knowledge graph. Something more like a post-it on your desk. A tracked task that you glance at later and decide what to do with. This directly solves the bug-next-door problem. The agent doesn’t need to fix the bug. It just needs a place to write it down.
Forced reflection. When the agent completes a task, make it record what surprised it, what broke, what it’d do differently. Not because the agent will learn from this next session (it’s stateless). But because you will. Those reflections accumulate. And when you have enough, you hand them back to the agent as its next prime directive: “Here are 12 learnings from the past week. Distill them into improvements.”
Now the agent’s full capability is pointed at code quality. Not as a side note in a markdown file. As the task.
The mental model that works: AI as a 10x exoskeleton, not a blind swarm. You’re the skeleton. You set direction, make architectural calls, and decide priorities. The AI amplifies your capability. But your judgment stays in the loop.
For small, scoped projects, one-shot AI implementations still work fine. But the moment scope grows, the moment decisions in session 5 affect session 25, that’s where you need the exoskeleton approach. Post-its for side-findings, forced reflections after each task, and periodic review cycles where you decide what the agent should improve structurally.
The tools for this are emerging. I’ve been building one called lazytask, which I’ll write about separately. Steve Yegge’s Beads takes a different approach, optimizing for multi-agent coordination and swarm workflows. The tools differ. The shared insight doesn’t: the answer to “my agent keeps making mistakes” is never a longer instruction file. It’s structural.
Next steps
If your CLAUDE.md is longer than a page, cut it in half. Then cut it in half again. Keep only lines that address problems your agent has hit more than once.
Ask yourself about every instruction: am I telling the agent what to think, or giving it a structure that changes what it does?
Audit your codebase for patterns. Are they the ones you want your agent replicating in every new file? Because it will. The codebase is the instruction. The CLAUDE.md is a footnote.
The broader principle: the best AI workflows aren’t built on better prompts. They’re built on better feedback loops. You, the human in command, deciding when and where to point the agent’s full capability at what actually matters.
If you want to hear more about the exoskeleton approach and the tools I’m building around it, I’ll be writing about lazytask soon. It’s open-source and built for developers who wants to utilize AI as an exoskeleton and partner, not a swarm.







