


The struggle is the same but different, if you’re a data-mature organisation with many teams and Data Products, or if you’re a small company that is just getting started on a data journey. Data will be flawed, bugs will be found and humans will make mistakes.
For your data to be valuable for your consumer, you must establish trust in the data and your team. Trust is created by actively working with data quality.
1. Prioritise with your consumer 🪮
There are many aspects to ensuring qualitative data. It should be well documented, truthful, up-to-date etc. To exemplify the complexity; good documentation is subjective, there are nuances of truth and there are different definitions of up-to-date. And you will never be able adress it all, at least not at once. You will need to prioritise.
Talking with your consumers will help you identify what quality aspects that are the most important for them and their use-cases.
A common approach is to define aspects of data quality using Data Quality Dimensions. DAMA published a research paper after analysing old and new literature on the topic, compiling a staggering list of ~60 dimensions. Using Data Quality Dimensions to frame your discussions, you should be able to identify what is the most important for your consumers.
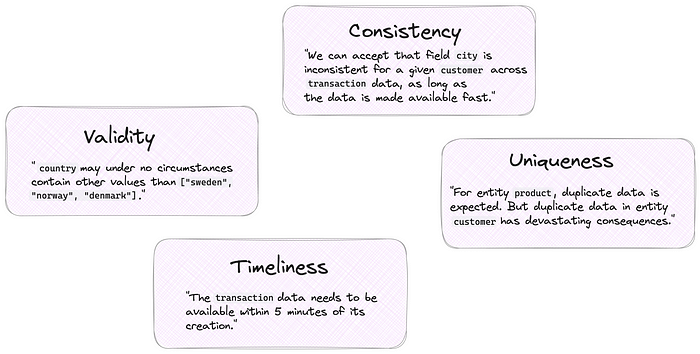
Perhaps Validity is really important for a certain field of an entity. For example field country is expected to be of type string and only ever be one of the values ["sweden", “norway”, “denmark"].
Or duplicate data is tolerated for certain entities, but Uniqueness is critical for another entity. For example in entity product it is acceptable that there are 3 records with product_id="product_4", perhaps the product has different versions. However for the entity customer it would be unacceptable if we have multiple customers with the same customer_id.
Maybe it is vital that the data is available within 5 minutes of its creation (Timeliness), more important than the data is consistent across records (Consistency). Say a record in entity transaction was populated by your workflow at 13:22, but the actual transaction occurred 13:05, then we have breached the timeliness requirement by 7 minutes. But it is acceptable that the value in field city changes from malmö to stockholm for customer customer_3 when grouping our transactions on customer_id; the customer performs the transactions from different locations.
To facilitate these discussions further, you can dive into your consumers Data Usage Pattern.
These discussions will allow you to prioritise where and how to adress the quality of your data. It will help you to focus on that which will be the most valuable for your consumers, and will also improve the relation and communication with your consumer.
2. Measure and share the quality 📣
Once you have identified what to prioritise, it is time to measure and follow up on these quality expectations.
You need to measure these dimensions, continuously, to find out if there is something in your data that you need to adress.
For the prioritised quality dimensions, you can define metrics that are calculated directly on top of your data. Together with a threshold value, you have a test that you can validate.

If you’re data is updated in batch less regularly, you might run these tests every time the data is updated, i.e. as a last step in your data transformation workflow. Or if you’re data is more realtime-oriented, you might run these tests on a schedule. Maybe some tests are run as a last step in your transformation, whereas other tests are run on a schedule.


These tests will either pass or fail. This means that at the time the test was executed, the data either meets the specific test requirement, or it doesn’t.
This is where the dimensions are helpful, as it is a way to aggregate the data quality requirements into groupings. Instead of just saying that a data quality test failed, we can present the flaws as limitations within a given Data Quality Dimension. For example, “there are problems with the uniqueness, however the timeliness is still 100%”.

Notifying your consumers pro-actively is really important for establishing and maintaining trust.
You want to avoid the consumer having to notify you about flaws in the data you own. That will immediately disrupt the confidence that your consumer has in your data and your reliability to deliver value.
I suggest keeping it simple when you’re getting started. Perhaps a certain dimension is critical, and a push-notification model is fitting to automatically notify your consumer if that dimension’s tests are failing. This way they can decide if they need to act on this information.
For other dimensions a pull-model might be more fitting. Adding the dimension’s scorings to the metadata connected to your data, will make it easier for future consumers to make an informed decision if they should start consuming your data or not. For example making this metadata visible where your data is discoverable (i.e. a data catalogue). Even better if this metadata is updated automatically after your tests are executed.

How to communicate effectively around the data quality of your data is no easy task. Like in the picture above you could simply provide a binary OK or FAIL for each dimension. Or you could aggregate all tests for a dimension of a given entity, visualising a percentage score. And do you only show the results of the latest executed tests, or all historic tests? A more extensive example of an implementation is that of Airbnb — Data Quality Score.
3. Act on test failures 🦸♀️
Identifying flaws in your data quality is one thing; hopefully you will want to address them. There are multiple of things to consider, depending on the setup of your data workflows, as well as the kind of dimension of the flaw.
Imagine tests fail which identify that inconsistent or duplicate data has been populated into your destination, do you:
- update your transformation workflow to avoid future flaws of that type?
- also backfill to fix the already populated inconsistent/duplicate data?
- or do you identify that this cannot be fixed, and that the data quality requirement is unrealistic?
For either one of these solutions, you will likely want to communicate with your consumer. “This won’t happen again in the future”, “the already populated inconsistent/duplicate data has been fixed” or “this will be a persistent issue”.

Imagine that your timeliness tests have failed, e.g. a source system isn’t sending data as expected. In this scenario you might not be in control of the source system, and there isn’t a lot that you can do. If this is a recurring issue, you might want to setup a SLA (Service Level Agreement) with the producer of that data so that you can make a more informed decision on how to adress these issues in the future.
I implore you to have a strategy in place for how to adress failing tests, to avoid alert fatigue.
Alert fatigue is a real thing. If you get too many alerts too often, especially alerts that you cannot do anything about, research shows that you will react less seriously and react with less immediacy.
Conclusion
Why did you read this article? You want the data that your team produces to be valuable, and actually used. To achieve this the data must uphold a certain level of data quality to truly be valuable.
I advice you to:
- prioritise Data Quality Dimensions together with your consumers, iteratively adding more dimensions and tests as your data product matures
- measure the prioritised quality expectation and use cases, and continuously share the results of the tests
- have a strategy for acting on data quality incidents.
I wish you the best of luck in your data endeavours!
Extra
If you’ve come this far, you might be wondering how to actually configure and run the data quality tests. There is an ocean of open source tools available for this. Below are a few.
- dbt tests, if you’re already using dbt. Supports
unique,not_null,accepted_values,relationshipsout-of-the-box. But also more extensive custom tests. - Soda CL checks, supports a bunch of integrations. Has a bunch of checks like
row_count,stddev,min,maxto name a few. - Deeque constraint validation, if you’re using Apache Spark.
- Cloud Data Quality, if your data resides in Google BigQuery. Has good support for grouping on Data Quality Dimensions.
- Great Expectations, supports many integrations. Also has good support for data profiling.




.png)


